De la esperanza a la integral de Lebesgue
No es que de la definición de esperanza de una variable aleatoria lleguemos al concepto de integral de Lebesgue, sino que nos apoyamos en el concepto de esperanza matemática que hemos visto varias veces en el blog, y lo utilizamos como escusa para explicar un concepto de integral que supera al tradicional de Riemann.
Hemos definido varias veces la esperanza de una variable aleatoria como la suma de los productos de los posibles valores de la misma por las probabilidades de que adopten esos valores.
Si X es una V.A. que puede tomar valores x1,...,xn con probabilidades p1,..,pn, (p1+...+pn = 1 ) entonces la esperanza de la variable X es:
E[X] = x1p1 + ... + xnpn
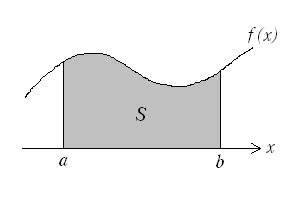
Cuando la variable es continua y toma valores en un intervalo [a,b], no podemos hablar de probabilidad de que tome un valor concreto, pues en el caso genérico, cada valor concreto tiene probabilidad nula de ocurrir (son infinitos los posibles). Hablaremos de densidad de probabilidad, entendiendo la densidad de probabilidad de un punto como el límite del cociente entre la probabilidad de un segmento que contenga a dicho punto y la longitud de dicho segmento, cuando ésta tiende a cero.
El operador esperanza se ha convertido en una integral . Sin embargo tenemos un problema: la integral habitual que se usa en ingeniería es la integral de Riemann, y se muestra absolutamente incapaz de hacer frente a problemas probabilísticos, incluso a algunos muy sencillos, como el siguiente:
¿Si escogemos un número en el intervalo [0,1] al azar cuál es la probabilidad de que el número escogido sea irracional?
La solución a este problema, casi trivial, muestra que la integral de Riemann es incapaz de afrontar contajes (pues una integral no es sino una forma de contar) en espacios abstractos como los espacios probabilísticos. Por ello hace falta una herramienta conceptual más elaborada que vendrá de la mano de Lebesgue.
Todo ello lo veremos en los próximos días. Daremos un repaso al concepto de Integral de Riemann, y veremos porqué en los casos más generales no es satisfactoria.
Hablar de integrales es hablar de maneras de contar. La combinatoria se puede definir como el arte de contar. Así lo hemos hecho en muchos posts precedentes. Sin embargo habría que hacer alguna precisión. No es lo mismo contar el número de ordenaciones de un conjunto finito de elementos que cumpla una propiedad concreta que contar los metros cuadrados que ocupa una superficie. La diferencia básica es que en el primer caso estamos en el dominio de los números enteros (o de los racionales si establecemos cocientes entre las cantidades previamente halladas), y en el segundo estamos en el dominio del continuo de los reales.
En cierto modo, estar en el dominio de R es cómodo: tenemos una serie de resultados que nos hacen agradable estar en el continuo de los reales, y que tienen que ver con temas topológicos muy profundos que ya se han discutido en el blog aquí.
Aunque es un tópico muy común, veremos que la integral de Riemann es una herramienta excelente para trabajar en "ambientes" en los que las buenas propiedades topológicas, tanto de los espacios como de las funciones a integrar, lo permiten. El problema vendrá cuando encontremos funciones, como la función de Dirichlet, que aunque definen problemas sencillos como el de encontrar la probabilidad de elegir un número racional al azar en el intervalo [0,1], no cumplen las "buenas propiedades" exigibles a las funciones para que sean integrables en el sentido de Riemann (las llamaremos funciones Riemann-integrables).
La meta será entonces encontrar una definición de integral que coincida con la de Riemann en las funciones Riemann-integrables, y que sea extensible a todas las funciones que se puedan definir de forma constructiva. Este reto es inmenso, y la forma de resoverlo me recuerda a la forma de Alejandro Magno de desatar el nudo gordiano. Para esta historia necesitaremos varios posts en los que recorreremos paisajes muy trillados y conocidos del cálculo diferencial; y otros menos conocidos y más exclusivos de la matemática menos "ingenieril".
Espero que sea un paseo agradable.















 ,
,  ,
,  y
y  . Aplicando esta regla, calculemos:
. Aplicando esta regla, calculemos:  , y 0 es divisible entre 13. Luego 4394 es divisible entre 13.
, y 0 es divisible entre 13. Luego 4394 es divisible entre 13.

 a cualquier subconjunto de A x A, y diremos que los pares (a, b) de dicho subconjunto están relacionados por
a cualquier subconjunto de A x A, y diremos que los pares (a, b) de dicho subconjunto están relacionados por  (a está relacionado con b por la relación
(a está relacionado con b por la relación  al conjunto de los números naturales,
al conjunto de los números naturales,  , considerando su producto cartesiano,
, considerando su producto cartesiano,  , podemos establecer la relación tal que relaciona a cualquier n1 con su doble, 2n1. Es claro que el conjunto
, podemos establecer la relación tal que relaciona a cualquier n1 con su doble, 2n1. Es claro que el conjunto  es un subconjunto de
es un subconjunto de  y por tanto la relación establecida es una relación binaria.
y por tanto la relación establecida es una relación binaria. .
. .
. implica que
implica que  .
. , decimos que
, decimos que  . ¿Es de equivalencia esta relación binaria? Para contestar afirmativamente tendremos que demostrar que se cumplen las tres propiedades. Para contestar negativamente, bastará con encontrar que falla una de ellas.
. ¿Es de equivalencia esta relación binaria? Para contestar afirmativamente tendremos que demostrar que se cumplen las tres propiedades. Para contestar negativamente, bastará con encontrar que falla una de ellas. . ¿Se cumple que
. ¿Se cumple que  . Pero dado
. Pero dado  .
. .
. y supongamos que
y supongamos que  .
. . Pero:
. Pero:
 .
. . Pero esto sólo es así si
. Pero esto sólo es así si  .
. , entonces
, entonces  .
. , definimos su clase de equivalencia
, definimos su clase de equivalencia  como el conjunto de los elementos de
como el conjunto de los elementos de  .
.
 como el conjunto de todas estas clases de equivalencia. Lo expresaremos formalmente como sigue:
como el conjunto de todas estas clases de equivalencia. Lo expresaremos formalmente como sigue:
 ,
,  , y que
, y que  .
.

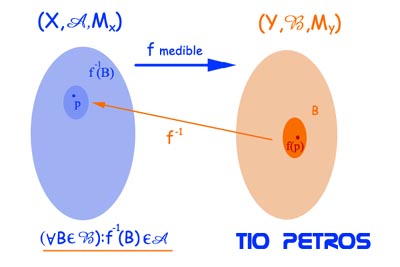 A lo largo de
A lo largo de 
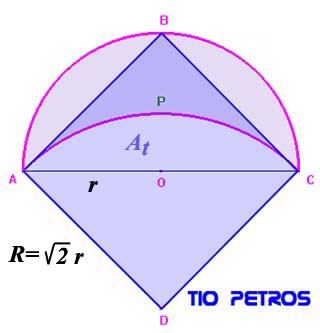 En una ocasión, hablamos de los
En una ocasión, hablamos de los 
 Otra muestra de la capacidad divulgativa del desaparecido Miguel de Guzmán ha sido publicada en España, una vez más por la editorial
Otra muestra de la capacidad divulgativa del desaparecido Miguel de Guzmán ha sido publicada en España, una vez más por la editorial  Dos reflexiones pueden servir para empezar este post, y ambas han sido realizadas bastantes veces desde este blog. La primera es que las conjeturas tienen en matemáticas un valor muy exiguo como afirmaciones, y un gran valor como acicate para nuevas investigaciones. De hecho, un sinnúmero de veces resultan ser falsas. Sin embargo el reto de demostrarlo ha espoleado a investigadores para transitar por caminos poco conocidos, alumbrando de paso rincones de la matemática, cuando no descubriendo zonas totalmente nuevas, más importantes que la mera dilucidación de la verdad o falsedad de la afirmación de la conjetura.
Dos reflexiones pueden servir para empezar este post, y ambas han sido realizadas bastantes veces desde este blog. La primera es que las conjeturas tienen en matemáticas un valor muy exiguo como afirmaciones, y un gran valor como acicate para nuevas investigaciones. De hecho, un sinnúmero de veces resultan ser falsas. Sin embargo el reto de demostrarlo ha espoleado a investigadores para transitar por caminos poco conocidos, alumbrando de paso rincones de la matemática, cuando no descubriendo zonas totalmente nuevas, más importantes que la mera dilucidación de la verdad o falsedad de la afirmación de la conjetura.
 Hemos explicado en post recientes que las raíces de la unidad se distribuyen a lo largo de la circunferencia unidad en el plano complejo, dividiéndola en n partes iguales. Vimos que cada uno de los valores de la raíz n-ésima de la unidad se podía expresar mediante el número complejo ei(2PI/n)k. Dando valores a k desde 1 hasta n obtenemos todas las raíces. No lo dijimos en su momento, pero a dichos números complejos unitarios se les denomina números de Moivre .
Hemos explicado en post recientes que las raíces de la unidad se distribuyen a lo largo de la circunferencia unidad en el plano complejo, dividiéndola en n partes iguales. Vimos que cada uno de los valores de la raíz n-ésima de la unidad se podía expresar mediante el número complejo ei(2PI/n)k. Dando valores a k desde 1 hasta n obtenemos todas las raíces. No lo dijimos en su momento, pero a dichos números complejos unitarios se les denomina números de Moivre .
 los correspondientes números de Moivre.
los correspondientes números de Moivre.