¿0+0+...=0?
 ¿Se puede obtener algo a base de sumar cantidades nulas?
¿Se puede obtener algo a base de sumar cantidades nulas?La pregunta parece ridícula...
Vayamos aproximándonos a la respuesta. Para empezar, si sumamos un número muy grande de cantidades muy pequeñas, podemos obtener cualquier cosa. Si el número de cantidades que sumamos tiende a infinito y el valor de cada cosa tiende a cero, estamos en la misma situación. Es lo que en el cole repetíamos; aquellos de cero por infinito es indeterminación .
Lo que queríamos decir con aquella frase no es sino algo obvio: cantidades muy pequeñas pueden dar como resultado cualquier cosa a condición de sumar las suficientes de ellas.Nada que viole la intuición ni las buenas costumbres.
Ya saben ustedes: tacita a tacita...
No es eso de lo que quiero hablar ahora. Quiero que las cantidades no sean despreciablemente pequeñas; quiero que sean estrictamente nulas. Cero patatero.
Ahora la cosa cambia, verdad?
En una primera aproximacion admitiremos que por mucho que añadamos nada a la nada que tenemos, seguiremos teniendo nada; y sin embargo, esto no es así. Todo depende de cuántas cantidades nulas estamos sumando.
Si la cantidad es finita; no hay nada que hablar: el resultado es cero. Si la cantidad es infinita, pues también. Puedo estar eternamente añadiendo ceros, que el resultado será siempre nulo. ¿O no?
Pues siento si rompo algún esquema, pero depende.
Recordarán si leyeron el artículo anterior, que había infinitos e infinitos. Si añadimos una cantidad infinita pero numerable (aleph-cero) de ceros, nuestra intuición sigue siendo correcta: resultado nulo. Pero si la suma se extiende a una cantidad no numerable de elementos (aleph-uno), la verdad es que podemos obtener un número tan grande como queramos, aunque cada uno de ellos sea estrictamente cero.
Tal es la potencia del primer infinito no numerable. ¿Les parece mentira? Fíjense en la figura. Tenemos un segmento de recta comprendido entre los puntos 0 y 1. Existe una noción muy concreta de medida para los conjuntos de elementos, que se llama medida de Lebesgue . Para nuestros propósitos actuales esta medida es idéntica a la longitud del segmento. Estaremos todos de acuerdo en que el segmento mide 1, y en que está formado por puntos. También estaremos de acuerdo en que la longitud de cada punto es EXACTAMENTE CERO. Pues eso, que la suma de todos esos ceros da uno.
Como vimos en el artículo anterior, el número de puntos de un segmento no sólo es infinito, sino que es un infinito no numerable, y ese es el quid de la cuestión.
______________________________________________________________________________________
PD. En una ocasión intenté convencer a un contertulio de esto que acabo de comentar, y no sólo no se lo creyó, sino que encima se enfadó conmigo. Espero que eso no me pase con ustedes...
 Miren un momento el símbolo que encabeza este artículo. Se trata de la primera letra del alfabeto hebreo; aleph . Detrás de este símbolo está el concepto más abismal de toda la matemática: el infinito, y un hombre: Georg Cantor.
Miren un momento el símbolo que encabeza este artículo. Se trata de la primera letra del alfabeto hebreo; aleph . Detrás de este símbolo está el concepto más abismal de toda la matemática: el infinito, y un hombre: Georg Cantor.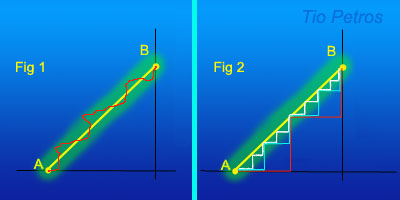 Una constante en este blog será la insistencia en que la intuición por sí sola no es una buena guía en matemáticas. Afortunadamente, tenemos una herramienta que nos sirve de brújula: el razonamiento riguroso. Lo que sigue es una muestra de los errores de la intuición, que son siempre debidos a dar por sentado cosas que no son ciertas; quizás porque tenemos una tendencia mental a extrapolar nuestras vivencias diarias a lugares en los que las cosas son ligeramente más complicadas.
Una constante en este blog será la insistencia en que la intuición por sí sola no es una buena guía en matemáticas. Afortunadamente, tenemos una herramienta que nos sirve de brújula: el razonamiento riguroso. Lo que sigue es una muestra de los errores de la intuición, que son siempre debidos a dar por sentado cosas que no son ciertas; quizás porque tenemos una tendencia mental a extrapolar nuestras vivencias diarias a lugares en los que las cosas son ligeramente más complicadas. Una de las formas más inconvenientes de buscar información fidedigna es buscarlo en internet. En otra historia comentábamos que dado que en el desarrollo decimal de pi está TODO, es lo mismo que decir que no hay nada. Nuestra querida web, en la que tantas horas metemos pone a nuestra disposición una parte importante de totalidad del saber humano, así como una gran parte de la imbecilidad humana. Al faltar un criterio de decisión fidedigno, estamos perdidos. Me gustaría poder decir que lo que ustedes lean aquí es básicamente correcto y honradamente escrito, pero al fin y al cabo, ustedes me encontraron en la calle. No se crean nada de lo que pone aquí, ni en ningún otro ciberlugar. Al menos, mantengan activa la hipótesis nula de que la web no es un buen lugar para buscar la verdad, sobre todo si no saben quién la ha escrito. Estaría bien recordar que hace muy pocos años; allá por la prehistoria, los escritos no firmados eran simplemente ignorados...
Una de las formas más inconvenientes de buscar información fidedigna es buscarlo en internet. En otra historia comentábamos que dado que en el desarrollo decimal de pi está TODO, es lo mismo que decir que no hay nada. Nuestra querida web, en la que tantas horas metemos pone a nuestra disposición una parte importante de totalidad del saber humano, así como una gran parte de la imbecilidad humana. Al faltar un criterio de decisión fidedigno, estamos perdidos. Me gustaría poder decir que lo que ustedes lean aquí es básicamente correcto y honradamente escrito, pero al fin y al cabo, ustedes me encontraron en la calle. No se crean nada de lo que pone aquí, ni en ningún otro ciberlugar. Al menos, mantengan activa la hipótesis nula de que la web no es un buen lugar para buscar la verdad, sobre todo si no saben quién la ha escrito. Estaría bien recordar que hace muy pocos años; allá por la prehistoria, los escritos no firmados eran simplemente ignorados...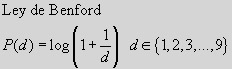 Los matemáticos se parecen a los niños en muchos aspectos. No hay nada que impulse tanto al trabajo como una pregunta sin responder. ¿Y eso porqué? parece ser la pregunta preferida. Algo así es lo que debió sentir el bueno de Simon Newcomb allá por 1.881 cuando observando distraídamente su libro de tablas de logaritmos, se dio cuenta de que estaba mucho más desgastada por las primeras páginas que por las últimas.
Los matemáticos se parecen a los niños en muchos aspectos. No hay nada que impulse tanto al trabajo como una pregunta sin responder. ¿Y eso porqué? parece ser la pregunta preferida. Algo así es lo que debió sentir el bueno de Simon Newcomb allá por 1.881 cuando observando distraídamente su libro de tablas de logaritmos, se dio cuenta de que estaba mucho más desgastada por las primeras páginas que por las últimas.
 Un número trascendente es un número real que no es raíz de ningún polinomio. Los que sí lo son se denominan algebraicos, y pueden ser tanto racionales como irracionales. Es curioso que siendo tan grande el número de polinomios posibles (de cualquier grado), casi todos los reales son trascendentes.
Un número trascendente es un número real que no es raíz de ningún polinomio. Los que sí lo son se denominan algebraicos, y pueden ser tanto racionales como irracionales. Es curioso que siendo tan grande el número de polinomios posibles (de cualquier grado), casi todos los reales son trascendentes. Para un servidor una de las mayores incógnitas del concepto de entropía es el motivo por el que tantas veces se emplea como comodín para las más peregrinas explicaciones. El concepto tiene un feeling indiscutible, pero lo malo es que transciende al mundo coloquial sin rigor alguno. Es de buen tono introducir la palabra entropía, aunque no se sepa muy bien a qué nos estamos refiriendo. Así, pude oír hace algunos años al escritor Fernando Sánchez Dragó manifestarse contra las corridas de toros porque añadían sufrimiento a la entropía del universo. El concepto al que hacía referencia de forma inadecuada, pueril y sin rubor alguno era evidentemente el concepto físico. En este ámbito, si un tertuliano quiere destacar no tiene más que unir el vocablo ciertamente eufónico de entropía al vocablo universo para obtener ...una frase redonda sin sentido alguno. (Me temo que este comentario es un poco off topic en Tio Petros).
Para un servidor una de las mayores incógnitas del concepto de entropía es el motivo por el que tantas veces se emplea como comodín para las más peregrinas explicaciones. El concepto tiene un feeling indiscutible, pero lo malo es que transciende al mundo coloquial sin rigor alguno. Es de buen tono introducir la palabra entropía, aunque no se sepa muy bien a qué nos estamos refiriendo. Así, pude oír hace algunos años al escritor Fernando Sánchez Dragó manifestarse contra las corridas de toros porque añadían sufrimiento a la entropía del universo. El concepto al que hacía referencia de forma inadecuada, pueril y sin rubor alguno era evidentemente el concepto físico. En este ámbito, si un tertuliano quiere destacar no tiene más que unir el vocablo ciertamente eufónico de entropía al vocablo universo para obtener ...una frase redonda sin sentido alguno. (Me temo que este comentario es un poco off topic en Tio Petros). Las paradojas no existen. Existen resultados que nos parecen paradójicos por que habíamos supuesto erróneamente que el resultado iba a ser otro. Y es que a partir de cierta hondura matemática, la intuición suele ser mala consejera.
Las paradojas no existen. Existen resultados que nos parecen paradójicos por que habíamos supuesto erróneamente que el resultado iba a ser otro. Y es que a partir de cierta hondura matemática, la intuición suele ser mala consejera.  Uno de los problemas básicos en matemática es el de optimización. Encontrar el punto en el que una determinada función alcanza el máximo (maximización) o el mínimo (minimización). Es tan obvio el interés de las técnicas de optimización que no vale la pena insistir en ello. Sin embargo, el problema es muy general, y no admite un tratamiento global. Para empezar, el punto que se quiere encontrar puede ser cualquier cosa, dependiendo del problema. Los alumnos de bachiller hallan puntos en los que una función real de variable real tiene un extremo, pero la vida real es mucho más diversa. Vamos a hablar de un problema concreto que es un paradigma de complejidad computacional: el Problema del Agente Viajero, conocido en computación como el problema STP, por sus siglas en inglés.
Uno de los problemas básicos en matemática es el de optimización. Encontrar el punto en el que una determinada función alcanza el máximo (maximización) o el mínimo (minimización). Es tan obvio el interés de las técnicas de optimización que no vale la pena insistir en ello. Sin embargo, el problema es muy general, y no admite un tratamiento global. Para empezar, el punto que se quiere encontrar puede ser cualquier cosa, dependiendo del problema. Los alumnos de bachiller hallan puntos en los que una función real de variable real tiene un extremo, pero la vida real es mucho más diversa. Vamos a hablar de un problema concreto que es un paradigma de complejidad computacional: el Problema del Agente Viajero, conocido en computación como el problema STP, por sus siglas en inglés. Es bastante habitual encontrarse con reseñas científicas en las que se explica que se acaba de encontrar el mayor número primo conocido. Se suele tratar de un número expresable como una enorme potencia de dos menos una unidad. ¿Es que todos los primos grandes son de esta forma?
Es bastante habitual encontrarse con reseñas científicas en las que se explica que se acaba de encontrar el mayor número primo conocido. Se suele tratar de un número expresable como una enorme potencia de dos menos una unidad. ¿Es que todos los primos grandes son de esta forma?