Paradojas infinitodimensionales ( y 2)
 Las respuestas dadas a la paradoja del post anterior por Eratóstenes y Tute son muy satisfactorias, y completamente correctas. Vamos a verlo en este post desde otro punto de vista que nos ayudará a tomar contacto con algunas nociones que necesitaremos para hablar algún día de los Espacios de Hilbert .
Las respuestas dadas a la paradoja del post anterior por Eratóstenes y Tute son muy satisfactorias, y completamente correctas. Vamos a verlo en este post desde otro punto de vista que nos ayudará a tomar contacto con algunas nociones que necesitaremos para hablar algún día de los Espacios de Hilbert .Cuando queremos definir un punto de un espacio de n dimensiones, debemos dar n valores, que son las n coordenadas que se necesitan para ubicar dicho punto en el espacio. La distancia euclídea de dicho punto al origen nos viene dada por el teorema de Pitágoras: será la raíz cuadrada de la suma de los cuadrados las n componentes.
De esta forma, podemos establecer una aplicación entre el conjunto de puntos del espacio y el conjuntos de números reales, de forma que a cada punto le corresponde el valor numérico de su distancia al centro. Si consideramos cada punto como un vector que nace en el origen y llega a dicho punto, dicho número se denomina norma del vector, y la aplicación se denomina norma del espacio, que ahora se dirá espacio normado. Existen otras normas que no son la euclídea, pero deberán cumplir una buenas propiedades para merecer tal nombre. Otro día hablaremos de ellas.
Un subconjunto del espacio se dice acotado si cabe dentro de una esfera maciza de radio suficientemente grande. Dicho de otra manera: si todos sus puntos están a una distancia no infinita del origen. (aquí el origen es arbitrario: podríamos decir si todos sus puntos están a una distancia no infinita de un punto dado).
Podeis observar que en el espacio de infinitas dimensiones tenemos una interpretación muy intuitiva de qué es cada punto: es una sucesión de infinitos números reales, sus coordenadas. Llegamos a la conclusión de que para que un punto esté a distancia no infinita del centro debe cumplirse que la suma de los cuadrados de sus coordenadas sea finita, pues sólo en este caso será finita la raíz cuadrada de dicha suma, y por tanto la distancia al origen. Esto ocurre por ejemplo para aquellos puntos que tengan todas las coordenadas igual a cero salvo un número finito de ellas, pero también puede ser que todas ellas sean diferentes de cero: debemos poner pues la restricción de que la serie que surge del sumatorio de los cuadrados de sus coordenadas sea convergente. Esta restricción es muy importante en los llamados Espacios de Hilbert , por ejemplo.
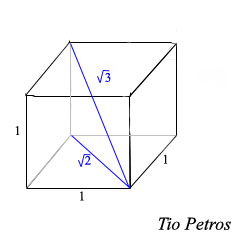
Si veis la definición de cubo macizo en este espacio, veremos que los puntos interiores tienen la restricción de que cada una de sus coordenadas es menor o igual a un número dado en valor absoluto. Los puntos que tengan todas el valor absoluto de sus coordenadas iguales a dicho valor son precisamente los vértices del cubo, si tenemos n dimensiones, como cada vértice puede tener cada una de sus coordenadas positivas o negativas, tenemos 2 n posibilidades, que nos da el número de vértices de dicho cubo.
En infinitas dimensiones, y pensando en el cubo de arista dada, infinitos son los vértices, pero en todos ellos el cuadrado de cada coordenada vale una cantidad no nula y mayor que cero ( al elevar al cuadrado (+z) ó (-z) obtenemos siempre una cantidad positiva); y la suma de todos estos cuadrados es infinita, luego cada uno de los vértices está a infinita distancia del origen. Poco importa que el tamaño de la arista: siempre que sea mayor que cero, obtenemos un objeto no acotado que no puede caben en esfera alguna.
Esto no ocurre para ningún valor del número de dimensiones del espacio, por grande que sea mientras sea finito; sólo ocurre para los espacios infinitodimensionales.
Por lo tanto, el error estaba en dar por buena la existencia de un cubo inscrito en la esfera.
 Nos es imposible visualizar un espacio de más de tres dimensiones, y sin embargo no tenemos ningún problema para trabajar con espacios de más dimensiones. Muchas veces, la extrapolación a mayor número de dimensiones es tan trivial, que en los libros de texto se omiten los detalles...
Nos es imposible visualizar un espacio de más de tres dimensiones, y sin embargo no tenemos ningún problema para trabajar con espacios de más dimensiones. Muchas veces, la extrapolación a mayor número de dimensiones es tan trivial, que en los libros de texto se omiten los detalles...
 Un lector me pregunta por la equivalencia topológica entre la esfera y el plano. Intuitivamente, parece ser que ambas superficies no son equivalentes. Después de todo, la esfera es una superficie muy diferente a un plano; no sólo por su forma (cosa poco importante en topología) sino por propiedades globales, como acotamiento.
Un lector me pregunta por la equivalencia topológica entre la esfera y el plano. Intuitivamente, parece ser que ambas superficies no son equivalentes. Después de todo, la esfera es una superficie muy diferente a un plano; no sólo por su forma (cosa poco importante en topología) sino por propiedades globales, como acotamiento.

 Centrémonos en nuestra pregunta: ¿puede existir algún poliedro, además del tetraedro (regular o no) tal que cualquier par de caras tenga una arista en común?
Centrémonos en nuestra pregunta: ¿puede existir algún poliedro, además del tetraedro (regular o no) tal que cualquier par de caras tenga una arista en común? Una de las posibilidades más increíbles de la matemática es que permite demostrar la existencia o inexistencia de objetos (incluso geométricos, que podamos construir o tallar en un trozo de madera) de los que poco sabemos: un puñado de propiedades tal vez, pero no su aspecto. Tengan presente que estoy hablando de existencia matemática, de forma platónica.
Una de las posibilidades más increíbles de la matemática es que permite demostrar la existencia o inexistencia de objetos (incluso geométricos, que podamos construir o tallar en un trozo de madera) de los que poco sabemos: un puñado de propiedades tal vez, pero no su aspecto. Tengan presente que estoy hablando de existencia matemática, de forma platónica.

 Hemos comentado varias veces que la palabra elemental en matemáticas es un arma de doble filo. Las demostraciones elementales de teoremas en teoría de números, por ejemplo son el paradigma de la extrema dificultad, mientras que utilizando el arsenal sofisticado del análisis complejo, las demostraciones muchas veces se realizan en dos renglones. Así mismo hay conceptos elementales que son difíciles de aprehender, y tan sólo son elementales porque no surgen de generalizar otros conceptos preexistentes.
Hemos comentado varias veces que la palabra elemental en matemáticas es un arma de doble filo. Las demostraciones elementales de teoremas en teoría de números, por ejemplo son el paradigma de la extrema dificultad, mientras que utilizando el arsenal sofisticado del análisis complejo, las demostraciones muchas veces se realizan en dos renglones. Así mismo hay conceptos elementales que son difíciles de aprehender, y tan sólo son elementales porque no surgen de generalizar otros conceptos preexistentes. .jpg) Prometimos demostrar que el conjunto de todos los números reales no era numerable, que es lo mismo que decir que no se podían poner en relación biunívoca con los enteros positivos. Otra forma de decirlo es que no podemos hacer un listado en el que figuren todos ellos.
Prometimos demostrar que el conjunto de todos los números reales no era numerable, que es lo mismo que decir que no se podían poner en relación biunívoca con los enteros positivos. Otra forma de decirlo es que no podemos hacer un listado en el que figuren todos ellos. 

 El post sobre el teorema de Lucas tendrá que esperar. Lo cierto es que hay algo que merece un apunte adicional a lo dicho anteriormente al respecto de la complejidad algorítmica. Tenemos la idea de que la cantidad de información, que medimos en bits, refleja de alguna manera el interés de aquello que consume esos bits: un mensaje de 1 mega tiene más información que un mensaje de 12 kB. Por otra parte, sabemos por experiencia que la longitud de un mensaje nada tiene que ver con su interés...
El post sobre el teorema de Lucas tendrá que esperar. Lo cierto es que hay algo que merece un apunte adicional a lo dicho anteriormente al respecto de la complejidad algorítmica. Tenemos la idea de que la cantidad de información, que medimos en bits, refleja de alguna manera el interés de aquello que consume esos bits: un mensaje de 1 mega tiene más información que un mensaje de 12 kB. Por otra parte, sabemos por experiencia que la longitud de un mensaje nada tiene que ver con su interés... Continuamos con lo prometido en el post anterior. Decíamos ayer que la omega de Chaitin (Chaitin es el de la foto)pertenecía a una clase de números reales verdaderamente malvados. Veamos porqué es esto así.
Continuamos con lo prometido en el post anterior. Decíamos ayer que la omega de Chaitin (Chaitin es el de la foto)pertenecía a una clase de números reales verdaderamente malvados. Veamos porqué es esto así.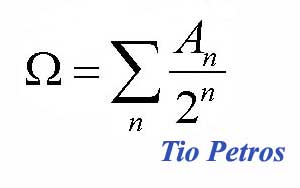 A Einstein no le habría gustado este post. Uno de los padres de la mecánica cuántica renegaba de la criatura con la frase Dios no juega a los dados.
A Einstein no le habría gustado este post. Uno de los padres de la mecánica cuántica renegaba de la criatura con la frase Dios no juega a los dados. Recuerdo que cuando aprendí lo que era un anillo y lo que era un cuerpo,allá por el bachiller, no supe entender la diferencia. Era evidente que había por ahí una propiedad que cumplían los cuerpos y no los anillos, pero aquello no parecía ser interesante, ni divertido. Como todo cuerpo era un anillo, parecía que los cuerpos eran más completos, y los anillos eran meros aspirantes a cuerpos.
Recuerdo que cuando aprendí lo que era un anillo y lo que era un cuerpo,allá por el bachiller, no supe entender la diferencia. Era evidente que había por ahí una propiedad que cumplían los cuerpos y no los anillos, pero aquello no parecía ser interesante, ni divertido. Como todo cuerpo era un anillo, parecía que los cuerpos eran más completos, y los anillos eran meros aspirantes a cuerpos. Kurt Gödel entra en escena
Kurt Gödel entra en escena 
 .
. =
= 

