Probabilidades extrañas
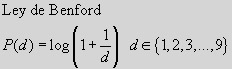
Los matemáticos se parecen a los niños en muchos aspectos. No hay nada que impulse tanto al trabajo como una pregunta sin responder. ¿Y eso porqué? parece ser la pregunta preferida. Algo así es lo que debió sentir el bueno de Simon Newcomb allá por 1.881 cuando observando distraídamente su libro de tablas de logaritmos, se dio cuenta de que estaba mucho más desgastada por las primeras páginas que por las últimas.
Newcomb era astrónomo y matemático, y por aquella época, las tablas de logaritmos eran el libro de cabecera de cualquier manipulador de cifras que se preciara. El desgaste diferencial del libro sólo podía tener una explicación: a lo largo de los años había consultado mucho más el logaritmo de los números que comenzaban por 1 que de los que comenzaban por números más altos.
Aquello parecía una hipótesis extraña: ¿porqué iban a ser más abundantes los números cuya primera cifra es 1, ó 2 que aquellos que empezaban por 8 ´0 9?
Nuestro astrónomo no pudo dar con razón alguna: sus números provenían de la observación de los astros principalmente: eran números sacados del espacio físico, y no debían tener ningún sesgo en su primera cifra. Se limitó a constatar que la ley de probabilidad de ocurrencia de números es tal que las mantisas de sus logaritmos son equiprobables.
El asunto no avanzó mucho hasta 1.938; año en el que el físico Frank Benford estudió 20.229 números provenientes de 20 muestras variopintas: constantes y magnitudes físicas, longitudes de ríos, direcciones de personas... incluso cifras sacadas de portadas de revistas. A partir de los datos extraídos del mundo real, postuló la llamada ley de los números anómalos de Benfordexpresable por la fórmula que abre este artículo.
Podemos ver en una gráfica las probabilidades de ocurrencia de cada dígito en primera posición, y veremos que la unidad ocurre casi un tercio de las ocasiones, y el 9 no llega al 5%.
Los números obtenidos del mundo real suelen ser dimensionales: podemos estar hablando de la renta per cápita de los nepalíes medida en rublos, de la superficie de los cráteres lunares en pies cuadrados o de la edad de los árboles de un bosque en quincenas. Si la distribución de Beford aparece en todas ellas, es evidente que debe ser invariante por cambio de escala. Si multiplicamos todos los datos por una constante, no se modifica la ley de aparición de la primera cifra. Por eso, son indiferentes las unidades de medida utilizadas. Esto es menos trivial de lo que parece: si multiplicamos por dos, todos los unos de primera cifra, que serán el 30% se nos van al garete; pero la cosa se compensa pues los cincos, seises, sietes, ochos y nueves...¡se convierten en unos!
Está claro que no siempre aparece esta ley: si tomamos los teléfonos de una provincia, no la encontraremos; y si medimos la longitud de las calles de una ciudad racionalmente urbanizada de cabo a rabo, tampoco: es donde más azar existe donde más fácil la encontramos.
¿Porqué funciona la ley de Benford en el mundo real¿
Se me ocurre un ejemplo para ver una explicación, sacado de la vida real:
Supongamos que en correos hacen una estadística sobre los números de portal de los destinatarios de las cartas a nivel nacional. Si todas las calles tuvieran 99 portales, 11 de ellos empiezan por 1 ( el portal 1 y los portales del 11 al 19) lo mismo podríamos decir de todos los demás números. Pero es que las calles tienen cada una un número de portales distinto; si la calle tuviera 19 portales, de ellos 11 empiezan por 1!!!
Vemos pues que salvo calles excepcionales de 9, 99, 999 portales, todas las demás favorecen los primeros dígitos pequeños, algunas extraordinariamente. Por ello, el fenómeno observado tiene su origen en la contribución de todos los casos posibles... y es la ley logarítmica de Benford.
En una ciudad artificial, que se hubiera construído racionalmente, con calles idénticas de 99 portales esto no ocurriría, pero la realidad es más compleja, y esta complejidad favorece a la ley de Benford.
Hay otro motivo matemático, pero es de bastante alto nivel. Sucede que la distribución de tiene una propiedad curiosísima: si un determinado fenómeno tiene n causas aleatorias y una de ellas sigue la distribución de Benford, la general también. La distribución de Benford es una especie de distribución que contamina a las demás. Así pues, cuanto más batiburrillo haya en la generación del fenómeno y más complejo e intratable sea, más fácil es que aparezca el 1 en primer lugar de los resultados obtenidos.
De hecho, existe una técnica de detección de fraude en declaraciones de renta basada en esto: si donde debiera aparecer Benford no aparece es un síntoma (que no una demostración categórica) de que los datos han sido amañados.
Para saber más podeis consultar aquíen castellano y
aquí en inglés.